
A Multi-Objective View of Decentralized Learning
 Roberto Morales
Roberto Morales Umberto Biccari
Umberto BiccariFind this post at CoDeFel blog.
1 Introduction
A common approach to decentralized learning is deceptively simple: each agent trains a model locally, and the resulting parameters are averaged. This idea, popularized through Federated Averaging [3], has become a cornerstone of modern distributed learning because it is easy to implement, scalable, and compatible with privacy-preserving settings.
To see why this is appealing, imagine a network of hospitals training a shared predictive model (see Figure 1). Each hospital keeps its own patient records locally, trains a model on its own data, and periodically sends updates to a central server. The server then combines these updates into a new shared model and sends it back to the hospitals. In this way, the system learns collaboratively without requiring direct data sharing.

Figure 1. A motivating example: several hospitals collaborate to train a shared predictive model. Each hospital has its own patient data and local priorities, while a central coordinator may impose global requirements such as regulation, fairness, or robustness.
Now ask yourself: What does it mean to train a single model in this setting?
At first glance, averaging seems not only reasonable but almost inevitable. If each hospital improves the model using its own data, then combining their updates should lead to a better global model. This intuition is particularly convincing when the hospitals see similar patient populations and optimize similar objectives (see [6]).
However, this reasoning begins to break down as soon as heterogeneity enters the picture. In realistic settings, hospitals may serve different populations, collect data under different protocols, and care about different performance criteria. One hospital may prioritize early detection, another may emphasize fairness across subpopulations, and a central authority may impose additional constraints related to regulation or robustness.
In such a situation, local updates may no longer point in compatible directions. The average of these updates may fail to represent a meaningful improvement for any individual agent. In some cases, it may even degrade local performance. This phenomenon, often referred to as client drift, is not merely a numerical inconvenience; it reveals a deeper modeling issue.
Averaging implicitly assumes that all agents are solving the same problem.
In reality, they are not. This mismatch between the assumptions behind classical aggregation schemes and the structure of real decentralized systems is precisely where a multi-objective viewpoint becomes useful.
2 From One Objective to Many
To better understand this limitation, let us reconsider the problem from first principles. Each agent i is naturally associated with its own objective function
C_i(\Theta),\quad i=1,\ldots, M,
which represents the empirical risk induced by its local dataset. These objectives need not be identical, because the underlying data distributions may vary substantially across agents.
At the same time, decentralized systems rarely operate without global requirements. In many applications, a coordinating entity introduces additional criteria into the learning process. These may encode fairness constraints, regularization terms, robustness requirements, or structural conditions intended to keep the learned model aligned with system-wide goals. We denote these coordinator-side objectives by
S_j(\Theta), \qquad j=1,\ldots,N.
Rather than forcing all these objectives into a single aggregated loss from the outset, we explicitly acknowledge their coexistence. This leads to the multi-objective problem [4]
\min_{\Theta} \left( C_1(\Theta),\ldots,C_M(\Theta), S_1(\Theta),\ldots,S_N(\Theta) \right).
This formulation captures both the local and global aspects of decentralized learning. It also changes the interpretation of the learning task. The goal is no longer simply to minimize one scalar loss. Instead, the goal is to understand and manage the trade-offs among several competing criteria.
3 A Single Parameter to Navigate Trade-Offs
To obtain a tractable optimization problem, we use a classical idea from multi-objective optimization: scalarization. The idea is to combine all objectives into a single surrogate function:
(1-\lambda)\frac{1}{M}\sum_{i=1}^M C_i(\Theta) + \lambda\frac{1}{N}\sum_{j=1}^N S_j(\Theta),
where \lambda\in[0,1) controls the relative weight of local and global objectives.
The parameter \lambda has a simple but powerful interpretation (see Figure [2]).
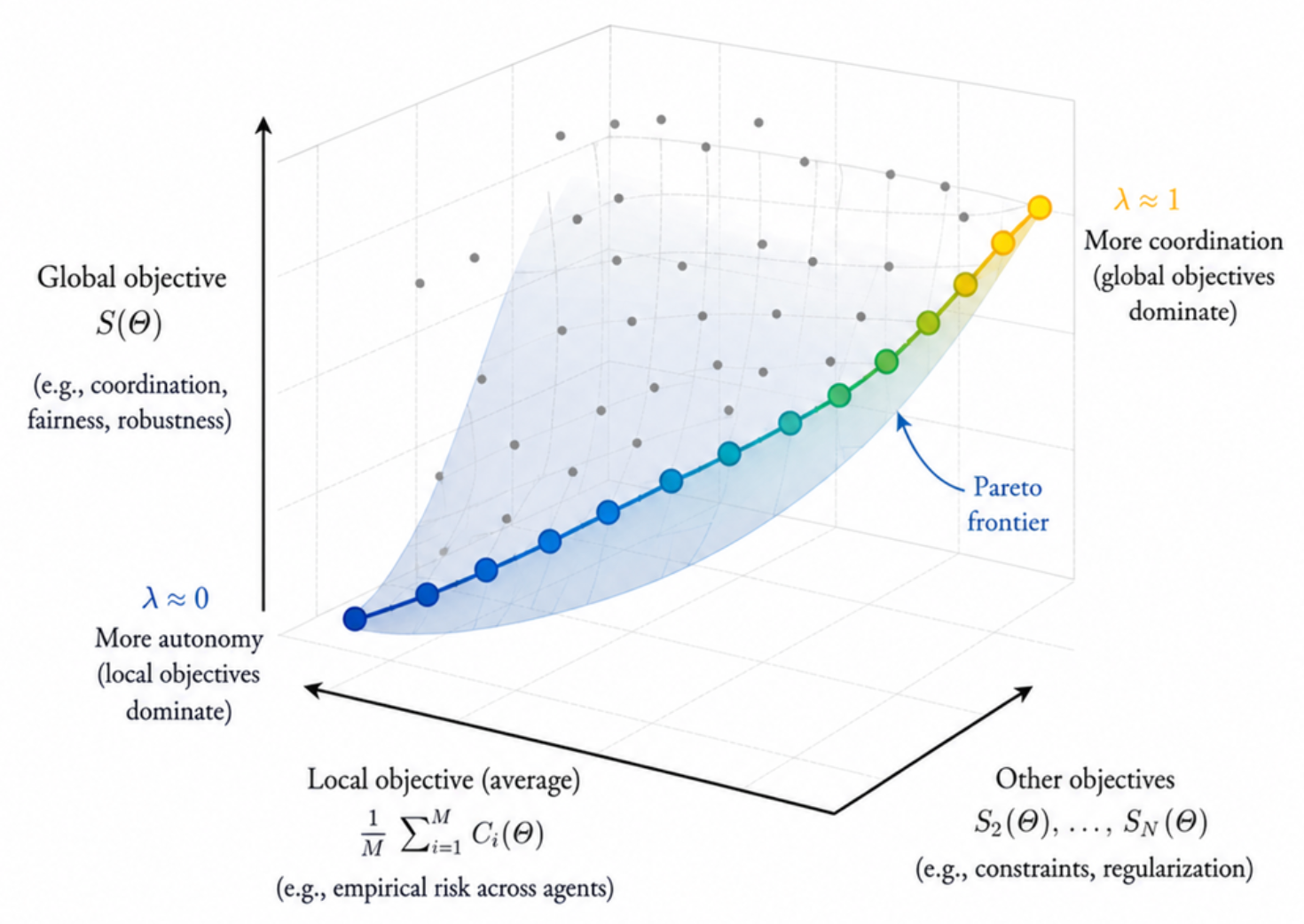
Figure 2. Illustration of the Pareto frontier in decentralized learning. Each point corresponds to a solution obtained for a given value of the trade-off parameter \lambda, balancing local objectives \frac{1}{M}\sum_{i=1}^M C_i(\Theta) and global objectives S_j(\Theta). As \lambda increases, the system transitions from locally-driven solutions (higher autonomy) to globally-coordinated ones.
On the one hand, When \lambda=0, the coordinator has no influence and the learning process is driven entirely by local objectives. On the other hand, as \lambda approaches 1, the coordinator-side objectives become dominant. Intermediate values of \lambda represent intermediate compromises.
Thus, \lambda acts as a control knob: it regulates how much the system prioritizes local autonomy versus global coordination. This is especially useful in applications where there is no universally correct balance, but rather a balance dictated by context.
4 Changing How Agents Learn
The introduction of scalarization does more than redefine the objective function. It also changes the way learning unfolds across the decentralized system.
In classical decentralized algorithms, coordination occurs mainly at the aggregation stage: agents train locally, then their parameters are averaged. In contrast, our approach incorporates coordination directly into the local updates. Each agent now solves a modified problem of the form
C_i(\Theta)+\alpha\sum_{j=1}^N S_j(\Theta),
where \alpha is determined by the trade-off parameter \lambda.
This small modification has an important consequence. Local updates are no longer driven solely by local data. They are also influenced by the coordinator’s objectives during the training process itself. Coordination is therefore not only imposed after local training; it becomes part of the learning dynamics.
Classical Federated Averaging is recovered as the limiting case \lambda=0. However, once \lambda>0, the algorithm changes qualitatively. The agents remain decentralized, but their local training is guided by global requirements. In [5], a qualitative analysis on the influence of \lambda in the training process is given.
What Do We Observe in Practice?
In [5], the theoretical framework described above raises a natural question: how does the trade-off parameter \lambda affect learning in practice?
To investigate this, we considered standard classification experiments on MNIST under both homogeneous and heterogeneous data distributions.
The codes used for this simulation can be found at FAU DCN-AvH GitHub
or, directly at: https://github.com/DCN-FAU-AvH/Decentralized-Learning.
5.1 Numerical Experiment: When Data Is Fragmented
We now consider a heterogeneous, non-IID data distribution. This experiment is designed to mimic the hospital example: each institution has access only to a partial view of the global population, and no local agent sees the whole classification problem.
Each of the five agents is assigned exactly two MNIST digit classes:
• Agent 1: digits 2 and 8,
• Agent 2: digits 4 and 9,
• Agent 3: digits 1 and 6,
• Agent 4: digits 3 and 7,
• Agent 5: digits 0 and 5.
The class assignments are non-overlapping. Each agent therefore trains on a restricted local problem and lacks direct information about the remaining eight classes. To avoid introducing data imbalance as a confounding factor, each agent receives the same number of samples: 8000 training images and 2000 validation images.
From a modeling perspective, this is exactly the situation described earlier: the agents are not solving the same problem. Each agent is optimizing a partial objective defined by its own local data.
A deliberately difficult regime. To stress the system, we consider a relatively large coordination parameter, \lambda=0.87. This places the method in a regime where the coordinator has strong influence, allowing us to observe how global guidance interacts with severe data heterogeneity.
As in the IID case, we set the number of local epochs to \tau=1. This is particularly important in the non-IID regime, since longer local training could cause agents to overfit to their incomplete datasets and produce updates that are harmful to the shared model.
The evolution of the agents’ performance is reported in Tables 1-2 and Figure 3.
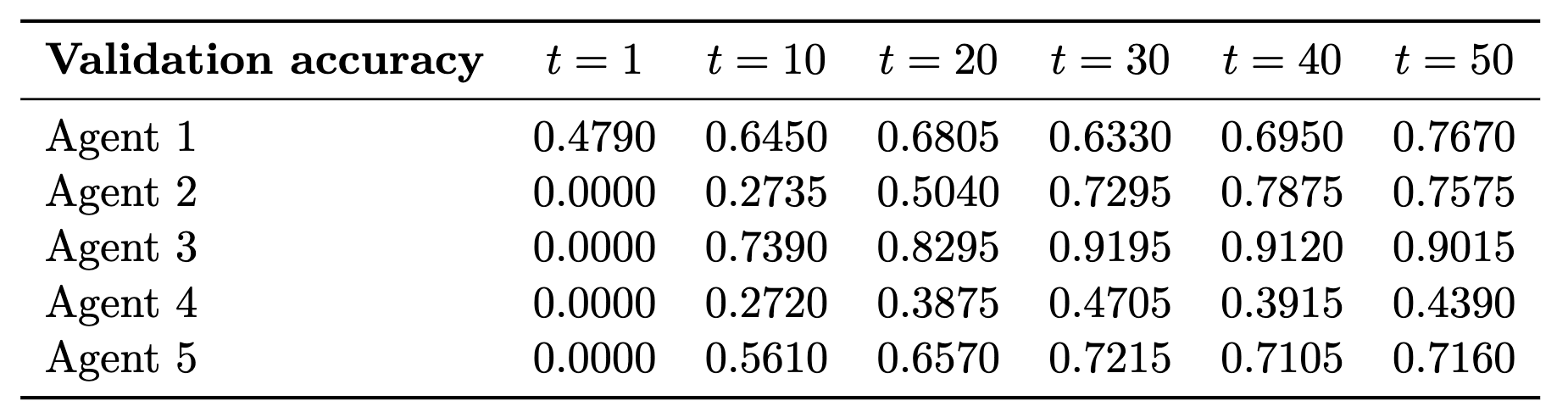
Table 1. Validation accuracy across agents under the non-IID data distribution with \lambda=0.87.
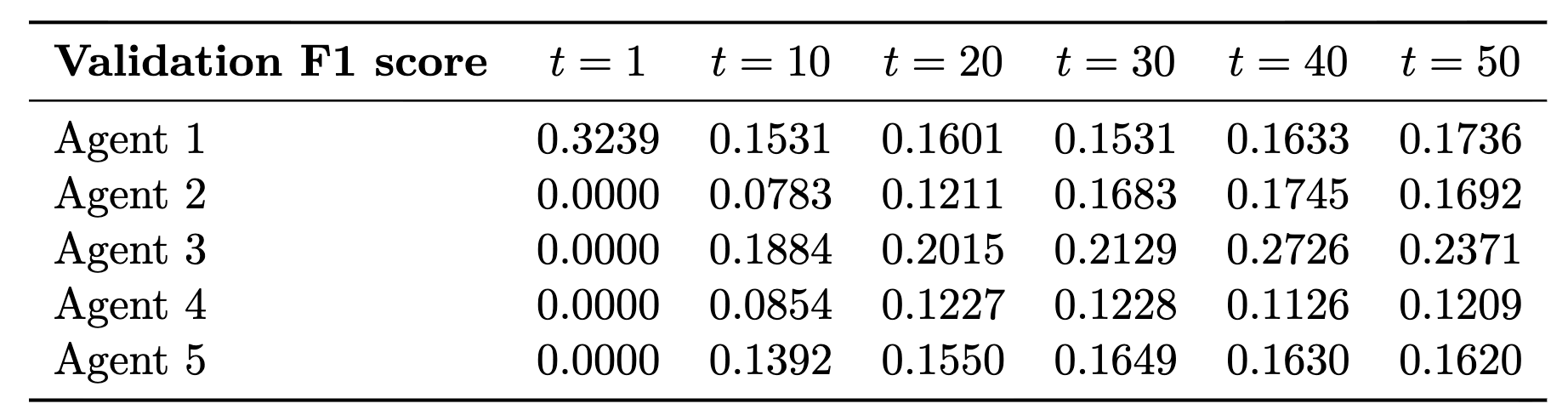
Table 2. Validation F1 score across agents under the non-IID data distribution with \lambda=0.87.
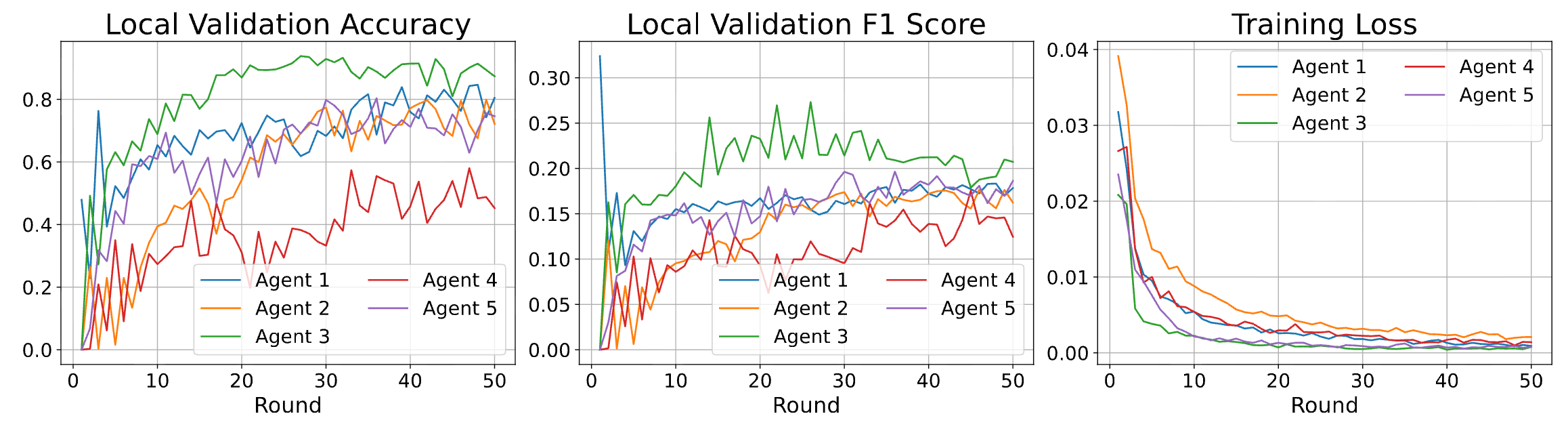
Figure 3. Evolution of the agents’ performance over 50 rounds in the non-IID regime.
First, the agents display strongly heterogeneous behavior, which is expected because each agent observes only two digit classes but is evaluated in a setting involving all ten classes. The local task is therefore intrinsically incomplete.
Second, despite this heterogeneity, the performance stabilizes as training progresses. The F1 scores remain relatively low at the agent level, reflecting the restricted information available to each agent. This should not be interpreted as a failure of the method, but as a consequence of the experimental design.
The important point is what happens globally. Even though no individual agent sees the full problem, the shared model aggregates partial information from all agents and achieves a test accuracy of 0.8056 and an F1 score of 0.7999 after 50 rounds. In other words, while each agent sees only a fragment, the decentralized system reconstructs a useful global model.
The role of \lambda. To better understand the effect of coordination, Table 3 compares several values of \lambda against two reference regimes: independent local training and centralized learning.
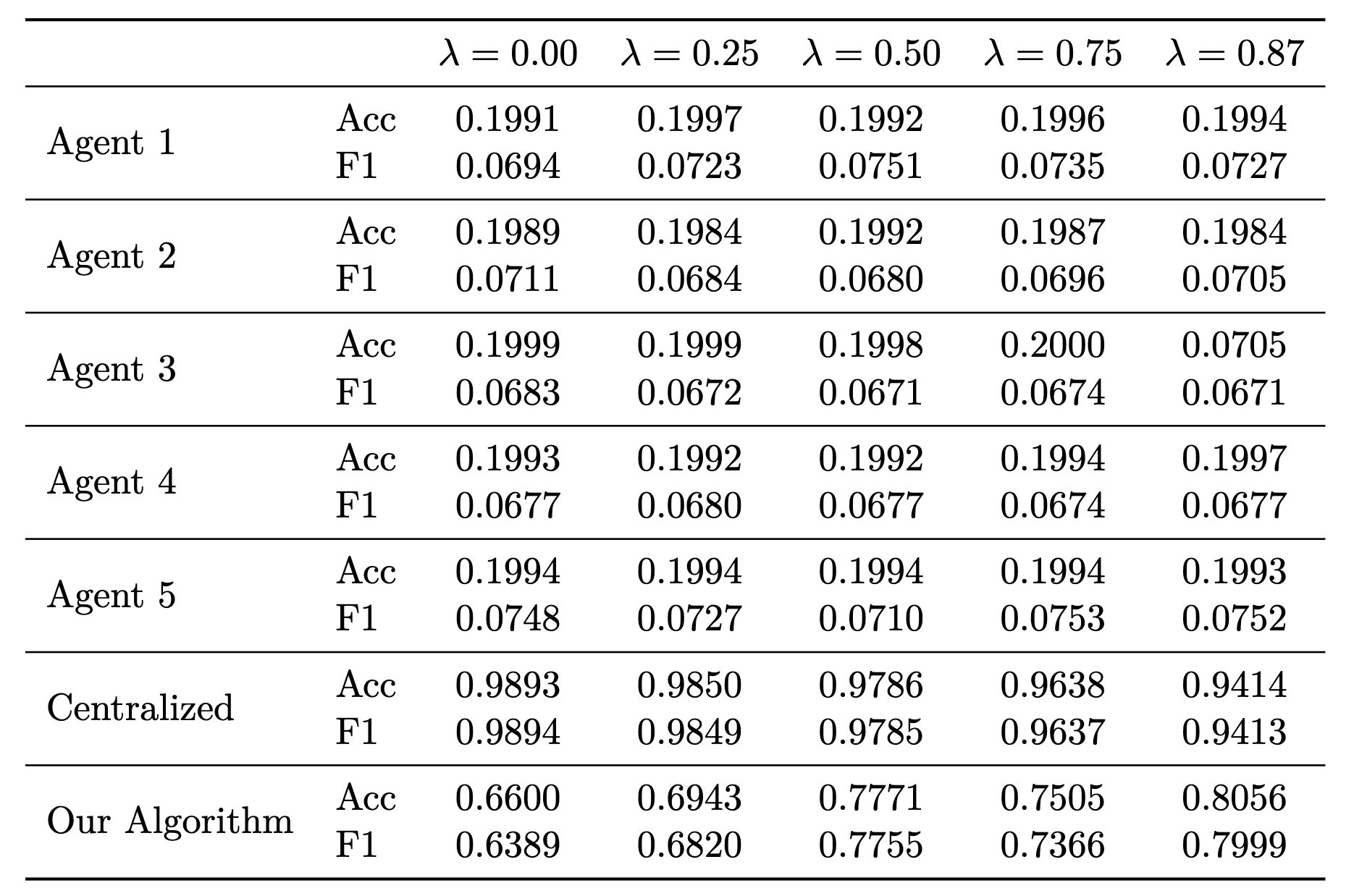
Table 3. Comparison across different values of \lambda under the non-IID setting. We report independent local training, centralized training, and the proposed decentralized algorithm.
The contrast is clear. Independent local training performs uniformly poorly, essentially because each agent is trained on only two classes but evaluated on all ten. Without information sharing, this task is not meaningful at the local level.
By contrast, the proposed algorithm significantly outperforms the local baselines for all tested values of \lambda, while remaining below the centralized upper bound. This is the expected behavior: centralized learning has access to all data at once, whereas the decentralized method must operate through partial information and aggregation.
The dependence on \lambda is especially informative. Larger values of \lambda can mitigate the effect of agent drift by increasing the influence of the coordinator. In this sense, the coordinator acts as a stabilizing force: it cannot fully replace missing data, but it can prevent local models from drifting too far toward narrow, agent-specific solutions.
From the perspective of the hospital example, this corresponds to a regulatory or institutional mechanism that keeps local learning aligned with global requirements. The resulting model may not match the centralized ideal, but it represents a robust and interpretable compromise under severe heterogeneity.
6 Open Questions and Future Directions
The present work opens several promising research directions, both at the theoretical and practical levels.
Beyond weighted scalarization. In this work, we have focused on a weighted-sum scalarization to navigate the trade-off between local and global objectives. While this approach is classical and well understood, it captures only a subset of the Pareto frontier in general settings. Extending the framework to more advanced scalarization techniques (such as Chebyshev norms or adaptive preference-based methods) could provide a richer exploration of trade-offs and allow for more flexible coordination strategies.
Adaptive and dynamic coordination. The parameter \lambda has been treated as a fixed quantity throughout the training process. However, in realistic systems, the balance between local autonomy and global coordination may evolve over time. Designing adaptive strategies in which \lambda is updated dynamically — for instance, based on performance metrics, fairness constraints, or system-level feedback — is a natural and challenging extension of the present framework.
Learning under severe heterogeneity. Our experiments highlight the fundamental role of data heterogeneity in decentralized learning. A deeper theoretical understanding of how heterogeneity affects convergence rates, stability, and generalization remains an open problem. In particular, quantifying the interplay between client drift, stochastic noise, and coordination strength is essential for designing robust algorithms in highly fragmented environments.
Beyond parameter averaging. Our formulation highlights a key limitation of classical approaches: parameter averaging is not always consistent with the underlying optimization problem, especially in non-IID regimes. This suggests the need for alternative aggregation mechanisms grounded in variational principles or functional averaging, which better reflect the structure of the global objective.
References
[1] S. P. Boyd and L. Vandenberghe (2004) Convex Optimization. Cambridge University Press[2] P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings, and others (2021) Advances and open problems in federated learning. Foundations and Trends in Machine Learning, Vol. 14, No. 1–2, pp. 1–210
[3] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. Aguera y Arcas (2017) Communicationefficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, pp. 1273–1282, PMLR
[4] K. Miettinen (1999) Nonlinear Multiobjective Optimization. Springer Science & Business Media, Vol. 12
[5] R. Morales and U. Biccari (2025) A multi-objective optimization framework for decentralized learning with coordination constraints, arXiv preprint arXiv:2507.13983
[6] J. Wang, Z. Charles, Z. Xu, G. Joshi, H. B. McMahan, M. Al-Shedivat, G. Andrew, S. Avestimehr, K. Daly, D. Data, and others (2021) A field guide to federated optimization. arXiv preprint arXiv:2107.06917
|| Go to the CoDeFeL blog main page